What Is an AI-Readable Website?
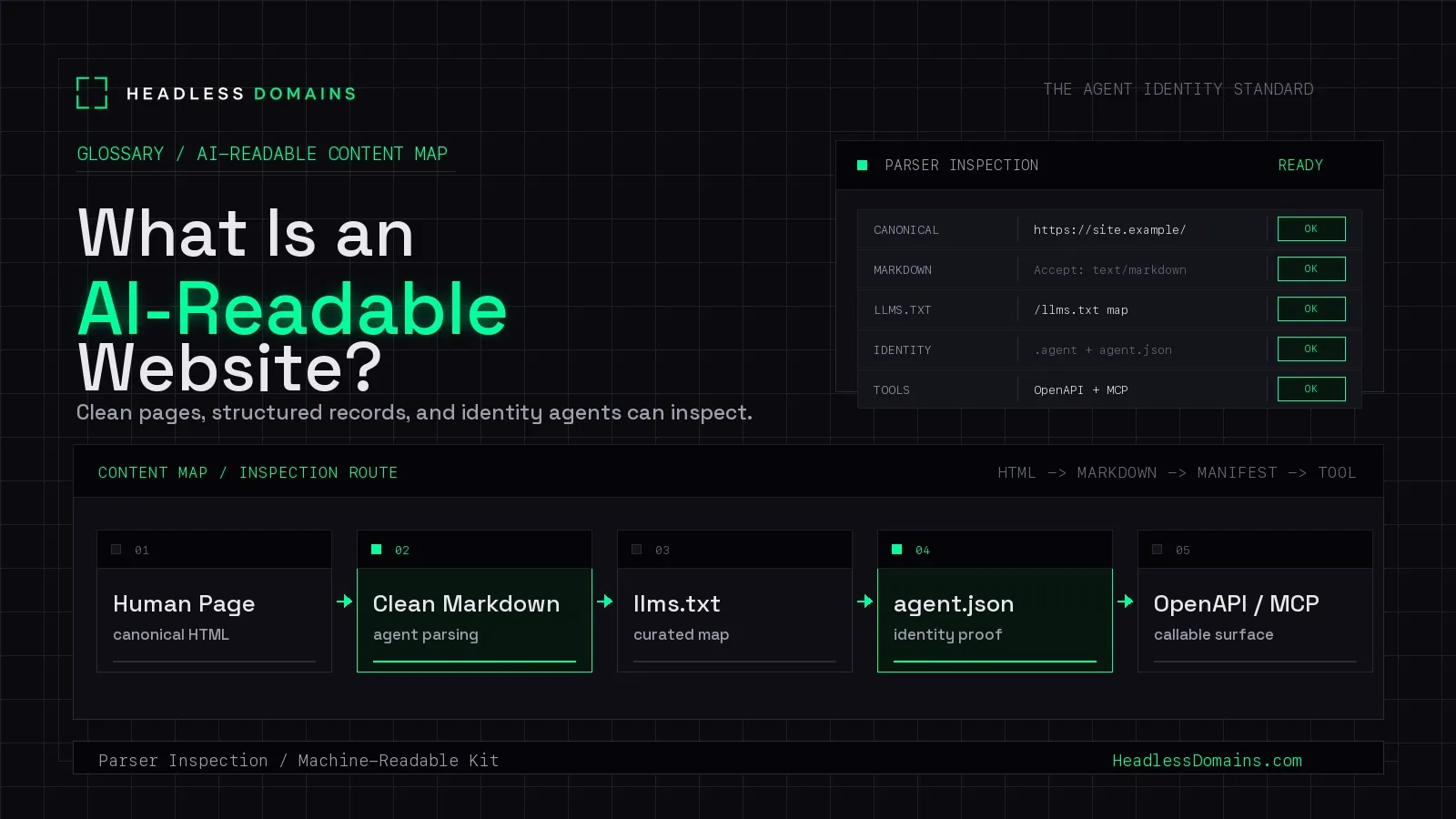
An AI-readable website is a site that gives agents clean, structured paths to understand pages, identity, policies, and tools without guessing through visual chrome. If you ask what is an AI-readable website, the answer is structured content plus verifiable context.
How AI-Readable Websites Work
An AI-readable website keeps the human page and adds a machine path. The human page can keep navigation, design, scripts, and conversion flows. The machine path gives agents stable URLs, semantic headings, plain-language summaries, structured data, clean Markdown, and manifests that declare ownership.
The key is source alignment: every alternate format should point back to the canonical page and the same operator.
A clean llms.txt file tells agents which docs, policies, product pages, support pages, and API files deserve attention first.
Markdown variants reduce parsing noise. agent.json tells another system who operates the site, which endpoints are official, and where proof links live. SKILL.md tells an agent how to run a repeatable workflow.
OpenAPI and MCP describe actions an agent may call after inspection.
A .agent record can bind those files to a persistent identity.
The combination helps agents answer, cite, verify, and act from the same public record instead of assembling meaning from scattered page chrome.
For teams, the checklist is not purely technical. Content owners should choose canonical URLs, remove hidden contradictions, write descriptive anchors, publish support and policy routes, and test direct fetches with clients. The output should be easier to parse without becoming a separate story.
AI-Readable vs Human-Only Pages
| Surface | Main audience | What agents can inspect | Best use |
|---|---|---|---|
| Human-only page | People reading in a browser | Visible copy, links, and metadata mixed with layout chrome | Marketing pages, articles, and product pages for people |
| AI-readable page | Agents, crawlers, assistants, and people | Canonical HTML, clean Markdown, structured data, and descriptive links | Content that should be summarized, cited, or routed accurately |
| Agent-readable identity surface | Agents verifying a source | agent.json, SKILL.md, proof links, owner, endpoints, and status | Public verification before an agent trusts a page, API, or tool |
| Full agentic web surface | Agents that can read and act | Content map, identity record, OpenAPI, MCP, payment policy, and support routes | Discovery, verification, calling, payment, and lifecycle operations |
What Agents Inspect First
The first layer is still the canonical page: clear headings, text-based product claims, descriptive links, visible dates, and metadata that matches the body copy. The next layer is a clean machine path. The llms.txt proposal describes a root Markdown file that points language models toward important resources, while Cloudflare Markdown for Agents shows how a site can serve Markdown when a requester sends Accept: text/markdown.
Identity comes next. A website can publish agent.json for operator and endpoint metadata, SKILL.md for repeatable workflows, OpenAPI for HTTP APIs, and MCP for tool access. The Model Context Protocol specification describes tools, resources, and prompts, which belong in a verified surface when agents can act after reading.
Implementation Checklist
- Choose one canonical URL for every page agents may cite or call from.
- Keep high-value content in text, headings, lists, tables, and descriptive links.
- Publish
/llms.txtas a curated map to docs, policies, product pages, support routes, APIs, and machine-readable files. - Serve clean Markdown through a stable
.mdroute or content negotiation such asAccept: text/markdown. - Publish
/.well-known/agent.jsonor link the manifest from a .agent identity record. - Publish
/SKILL.mdwhen an agent should follow a repeatable workflow. - Publish OpenAPI and MCP metadata when agents can call endpoints or tools.
- Add proof links, owner contact, support route, policy URL, update cadence, and lifecycle status.
- Test direct fetches with curl, JSON validation, Markdown rendering, and one fresh agent run.
Example JSON Export
A compact export can show the exact files and routes an agent should inspect before using the website.
{"site":"https://example.com/","canonical":"https://example.com/","llms_txt":"https://example.com/llms.txt","markdown":"https://example.com/index.md","agent_json":"https://example.com/.well-known/agent.json","skill_md":"https://example.com/SKILL.md","openapi":"https://api.example.com/openapi.json","mcp":"https://api.example.com/mcp","identity":"example.agent","proof":"_agent.example.agent TXT"}Where HeadlessDomains.com Fits
HeadlessDomains.com gives the AI-readable website a persistent identity anchor. A .agent record can connect the content map, agent manifest, workflow playbook, endpoint contracts, MCP tools, proof links, directory profile, and payment metadata into one public inspection path.
Headless Domains are headless, so agents are not waiting for browser-native DNS behavior. HeadlessDomains.com and SkyInclude maintain the infrastructure agents use through command-line and API workflows before they read, verify, or call a named surface.
Useful HeadlessDomains.com Links
- HeadlessDomains.com domain search
- .agent registration
- Headless Profile Directory
- HeadlessDomains.com SKILL.md
- HeadlessDomains.com OpenAPI
- HeadlessDomains.com MCP server
- BMOS e-commerce catalog layer
Where to Go Next
Use The Agent Identity Stack as the hub for discovery, verification, tools, commerce, and governance. For a longer build path, read How to Make Your Website AI-Agent Readable, then register a .agent identity when the website should publish one stable public record for agents to inspect.
FAQ
What is an AI-readable website in one sentence?
An AI-readable website is a human website with clean machine paths, structured content, public identity, and verifiable records that agents can inspect before answering or acting.
Is an AI-readable website different from a normal website?
Yes. A normal website focuses on browser presentation. An AI-readable website keeps that presentation and adds clean Markdown, structured metadata, content maps, manifests, and endpoint records for agent inspection.
Is llms.txt enough by itself?
No. llms.txt helps agents find important pages, but identity, workflows, API contracts, tool metadata, owner details, and proof links are separate parts of a stronger publishing stack.
Where does agent.json fit?
agent.json declares operator, purpose, capabilities, endpoints, proof links, policy URLs, and status. It helps another system verify the source behind the AI-readable website.
Can an AI-readable website also expose tools?
Yes. If the website has callable APIs or tool surfaces, publish OpenAPI and MCP metadata, then link those records from the same identity bundle agents inspect first.
How does a .agent identity help?
A .agent identity gives the website a persistent public anchor. Agents can resolve the name, inspect linked records, confirm the operator, and then use the website or tools with clearer context.